
A neutral metadata repository and systematic framework for extracting, coding, and quality-assuring RCT evidence from low- and middle-income countries.
Open-source, open-access public good. All protocols, coding decisions, and QA measures are publicly documented.
Detailed protocols let third parties replicate and verify every step of the review and coding process.
A carefully selected minimum set of fields balances comprehensiveness with feasibility across disciplines.
Staged workflow and custom data entry platform support extraction from thousands of RCTs at high quality.
Metadata schema and structured instruments with fields, validation rules, and skip logic for systematic extraction at scale.
Free, public platform with integrated QA and support — also usable as a general survey tool by external users.
Comprehensive, interoperable database of coded RCTs from low- and middle-income countries, comparable across studies.
Downloadable datasets and interactive evidence presentations for researchers, policymakers, and practitioners.
Training courses, technical materials for coders and external users, and open-source data files explaining assumptions underlying standard meta-analysis packages.
Peer-reviewed journal article with a valid DOI, available in English.
Implemented in low- or middle-income countries per World Bank income group classifications (updated annually).
RCTs evaluating field or policy interventions — field experiments, A/B tests, and cluster-randomized trials.
At least one quantitative treatment effect with a point estimate and precision (SE, CI, p-value, or test statistic).
Lab-in-the-field, survey-design interventions, hypothetical/pre-analysis-plan-only studies are not eligible.
Currently targeting 1,000 RCTs coded by human coders. Criteria may expand after the pilot phase.
IDEAL's Approach
IDEAL functions as a neutral metadata repository — it does not assign quality ratings or risk-of-bias scores to studies. Rather than determining which studies are "high quality" or "low quality," IDEAL captures the raw information that enables secondary users to conduct their own assessments according to their preferred methodologies and frameworks.
Fields That Support Risk-of-Bias Assessment
Attrition
Sample sizes at randomization and analysis enable calculation of participant attrition.
Selection Bias
Randomization method and unit of randomization inform assessment of selection bias.
Analytical Validity
Documented analytical approaches allow evaluation of appropriate handling of clustering and stratification.
Compatible Frameworks
Users can apply Cochrane risk-of-bias, WWC threshold criteria, or any other framework to IDEAL data.
Document the experimental architecture — number of experiments, interventions, study arms, outcomes, specifications, data collection rounds, and exhibits containing results. Then confirm which treatment effects exist per outcome using IDEAL's prioritization hierarchy, organized exhibit by exhibit.
Supervisor review & approval required before Stage 2Collect comprehensive metadata: intervention descriptions, outcome definitions, sample characteristics, and numerical treatment effect values with precision measures and statistics needed for effect size standardization. All data auto-links to Stage 1 structural elements.
Double-coded by two independent codersCoders are hired competitively and complete a full training program — protocols, videos, and 10 practice papers with PI-verified ground truth. Weekly office hours throughout.
The data entry platform enforces automated real-time consistency checks and skip logic, catching errors and logical contradictions as coders work.
After Stage 1, supervisors review and approve all entries before coders can proceed. Supervisors may request resubmission for major errors; minor corrections are made directly.
Two independent coders complete Stage 2 for every paper without seeing each other's work. Supervisors compare entries, identify discrepancies, and produce final consensus values.
Principal Investigators verify 20% of fields across 20% of randomly selected papers initially, reducing to 10% as quality stabilizes. Errors flagged by PIs are corrected by supervisors.
PI-cleared data is processed to check and remove outliers. A feedback form on the IDEAL platform allows users to flag issues for continuous improvement.
An entry is accurate if it correctly represents what is described in the manuscript, verified by a PI for fields requiring inference. Tracked as: fields verified accurate ÷ total fields — calculated per paper, per section, and per coder.
Based on PI spot-check comparisonsAn entry is reliable if two coders extract the same information in the same way. Tracked as: double-coded extractions in agreement ÷ total papers coded — calculated per field and per section.
Based on Stage 2 double-coding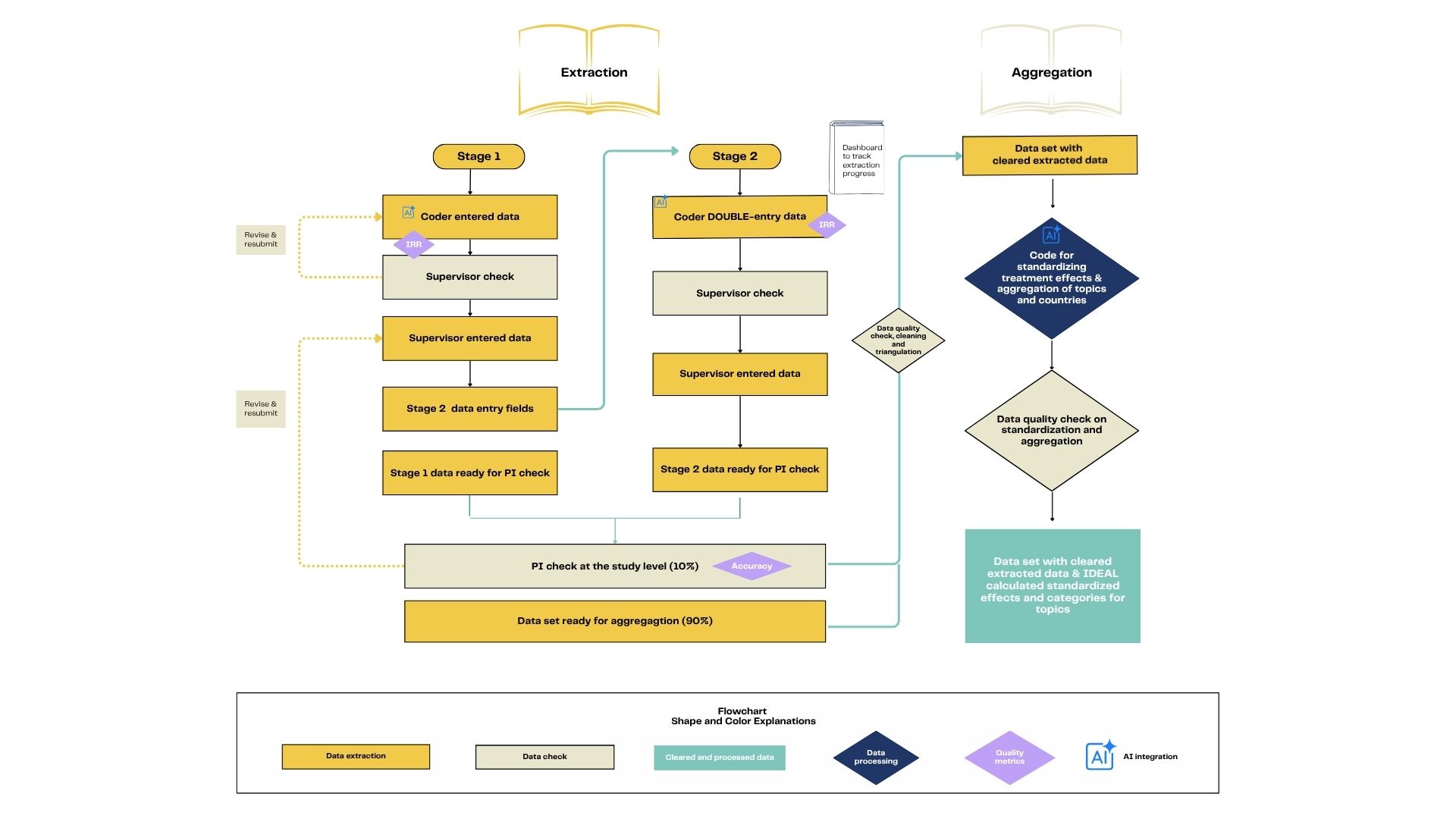
IDEAL Data Extraction Workflow — Figure 1 in the full guide